When doing a Live Migration from SCVMM (System Center Virtual Machine Manager) with VSM, moving a Virtual Machine from one Cluster to another Cluster and at the same time also to a new Storage Location, you are getting an error message similar to this:
|
|
Error (12700) VMM cannot complete the host operation on the HOST07.FABRIC.DOMAIN.COM server because of the error: Virtual machine migration operation for 'markustest01' failed at migration source 'HOST07'. (Virtual machine ID FAA0957A-4AF9-4B84-8AE9-2E9BC56CA9A6) Migration did not succeed. Could not start mirror operation for the VHD file '\\FASOFSL02.FABRIC.DOMAIN.COM\CSV02\markustest01-1\FAS2012R2-001G2.vhdx' to '\\FASOFS01.FABRIC.DOMAIN.COM\vDisk03\markustest01-6\FAS2012R2-001G2.vhdx': 'General access denied error'('0x80070005'). Unknown error (0x8001) Recommended Action Resolve the host issue and then try the operation again. |
The strange thing is that there is a destination folder in the new location, it’s just does not copy content to that folder and aborts with the Access Denied error. But If you shutdown the VM first, so it’ s just a migration over the Network, it works!
The solution is to give the SOURCE Cluster Write Access on the DESTINATION Storage. When you do a VSM Migration, the destination Hyper-V host, creates the Directory on the SOFS Node, but it’s the Hyper-V Host that owns the VM that copies the VHD’s files to the destination storage. And as the current owner, by default does not have access to write there, it will fail. One could think that VMM should grant permissions to a host when VMM knows that the host needs to write in the location?
Maybe it’s fixed in the next version, but until then, there are two ways to do this.
Solution 1) In VMM add the Destination SOFS Shares as Storage on the Source VM Hosts like this. That will make VMM add the VM Hosts with Modify Permissions in the SOFS Shares so it can write there.
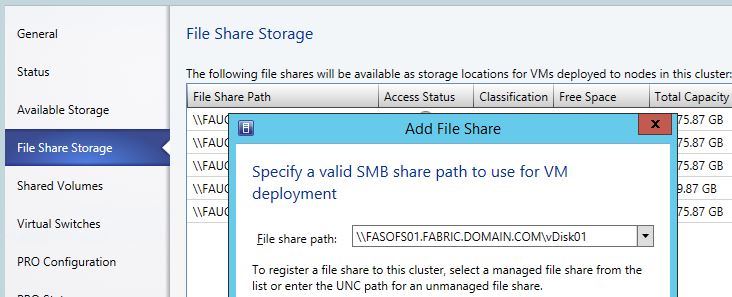
This works quite fine, if the Hyper-V Clusters and all Storage is located in roughly the same location. But if you have one compute cluster with storage in one location, and another compute cluster with storage in another location. There is then a risk that you may be running VM’s cross the WAN link.
Solution 2) This is the one we used. By not using VMM to grant permissions to the shares, but rather do it manually we achieve the same solution as above but with the added benefit that a new VM will always be provisioned on the local storage and there is no (or a lot less) risk of running a VM cross the WAN link. Yes, it’s still technically possible to do it, but no one will by accident provision a VM that uses storage in the other datacenter.
You can either add each node manually, so we have created a “Domain Servers Hyper-V Hosts” security Group in AD where we add ALL Hyper-V hosts to during deployment. And then added that group to the Share and NTFS Permissions. All Hyper-V hosts will then automatically have write access to all locations they may need.
I wrote these two short scripts to query the VMM Database for the available SOFS Nodes and use powershell to grant permissions to the share, and to NTFS.
As all our SOFS Shares were called vDiskXX or CSVXX (where XX is a number) I just used a vDisk* and CSV* to do the change on all those shares. You might have to modify it a little to suit your name standard.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Grant SOFS FileShare permissions to group: Domain Server Hyper-V Hosts $group = (Get-ADGroup "Domain Server Hyper-V Hosts").Name $servers = ((Get-SCStorageFileServer | select StorageNodes).storageNodes).Name foreach ($srv in $servers) { Get-SmbShare -CimSession $SRV -Name vDisk* | Grant-SmbShareAccess -AccountName $group -AccessRight Full -Force Get-SmbShare -CimSession $SRV -Name csv* | Grant-SmbShareAccess -AccountName $group -AccessRight Full -Force } # Grant NTFS permissions to group: Domain Server Hyper-V Hosts $FileShares = Get-SCStorageFileShare foreach ($share in $FileShares.SharePath) { $acl = get-acl $share $group = (Get-ADGroup "Domain Server Hyper-V Hosts").Name $permission = "$env:USERDNSDOMAIN\$group","FullControl", "ContainerInherit, ObjectInherit", "None", "Allow" $accessRule = new-object System.Security.AccessControl.FileSystemAccessRule $permission $acl.SetAccessRule($accessRule) $acl | Set-Acl $share -Verbose } |
Updated Script (2016-02-04):
I got a report that the script was getting an error on some servers, which I managed to reproduce. Here is an alternative version where it will connect to the server and execute the ACL change locally via invoke-command. It’s also only changing permissions on Continuously Available (SOFS) shares.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
$FileShares = Get-SCStorageFileShare | where StorageClassification -notlike "Library" foreach ($share in $FileShares) { $SMBServer = $share.StorageFileServer.StorageNodes[0].Name $SOFSCluser = $share.StorageFileServer.Name Write-Output "Connecting to Node: $SMBServer for SOFS Cluster: $SOFSCluser" Invoke-Command -ComputerName $SMBServer -Verbose -ScriptBlock { # Change to the right Group Name here $Group = "FABRIC\Domain Server Hyper-V Hosts" $SOFSShares = Get-SmbShare | where { $_.ContinuouslyAvailable -eq "True"} $SOFSShares | Grant-SmbShareAccess -AccountName $Group -AccessRight Full -Force foreach ($SOFSShare in $SOFSShares) { $ShareDir = $SOFSShare.Path $acl = (Get-Item $ShareDir).GetAccessControl('Access') $permission = "$Group","FullControl", "ContainerInherit, ObjectInherit", "None", "Allow" $accessRule = new-object System.Security.AccessControl.FileSystemAccessRule $permission $acl.SetAccessRule($accessRule) Write-Output "Set ACL on: $ShareDir" $acl | Set-Acl $ShareDir } } } |