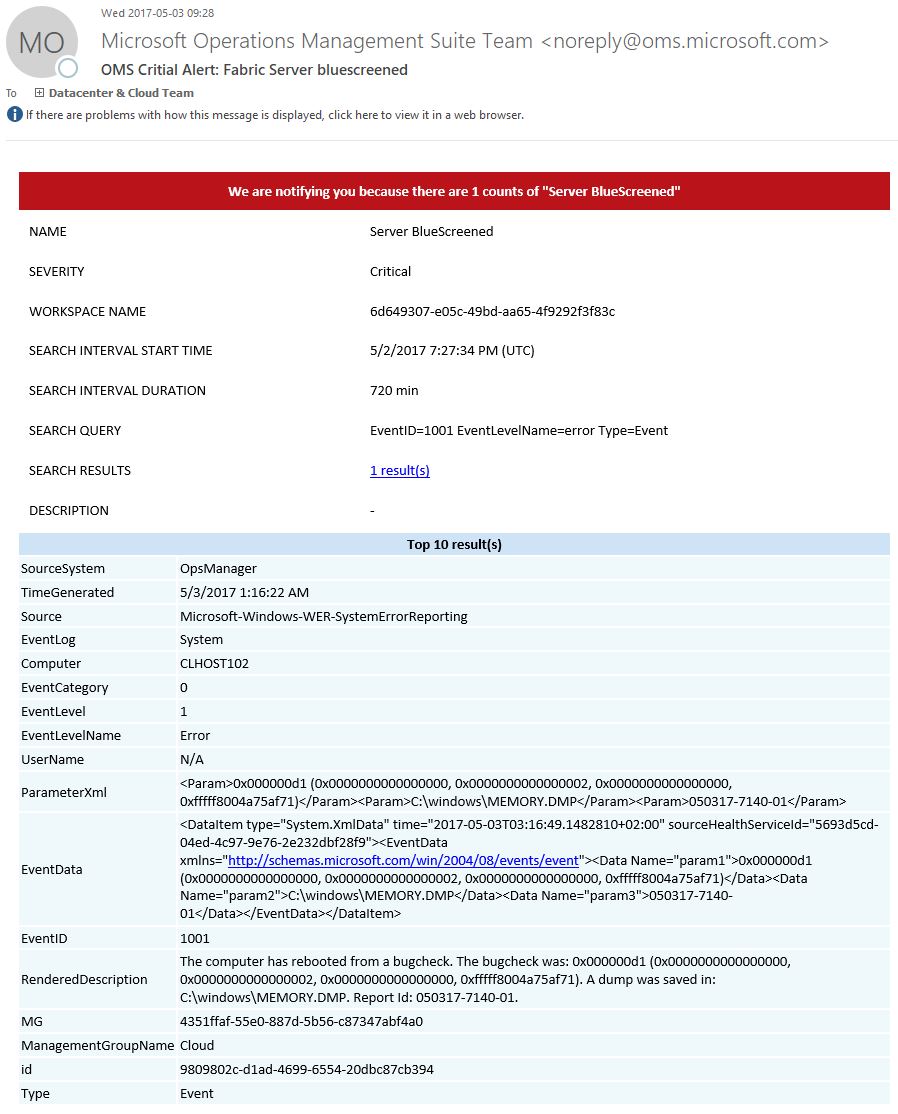
Using Powershell to locate your Geographical Location with the help of GeoLocation (IP-Address) is quite easy, cool and useful!
When we build Private and Hybrid Clouds across the globe in various countries and continents I want to make sure the Active Directory PDC Emulator is using a valid time source based on that location.
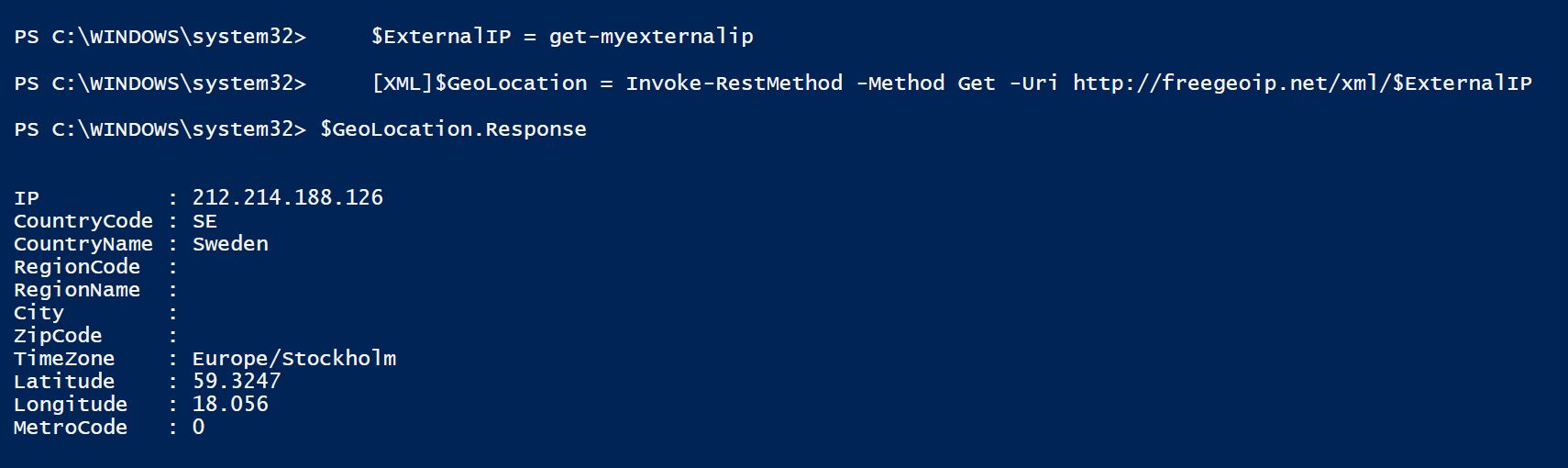
So with this small script (it’s using multiple WebServices to cycle through until it gets an answer) we can get a rough location for where we are and in my case it’s usually enough to know what country the datacenter is in.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
function get-myexternalip() { $urls = "http://whatismyip.akamai.com", "http://b10m.swal.org/cgi-bin/whatsmyip.cgi?just-ip", "http://icanhazip.com", "http://www.whatismyip.org/"; $RxIP = "(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})"; $ip = "Unknown"; Foreach ($address in $urls) { try { $temp = wget $address; $www_content = $temp.Content; if ( $www_content -match $RxIP ) { $ip = ([regex]($rxip)).match($www_content).Value break } } catch { continue } } return $ip } $CheckNetwork = Test-NetConnection -CommonTCPPort HTTP freegeoip.net if ($CheckNetwork.TcpTestSucceeded -eq $True) { $ExternalIP = get-myexternalip [XML]$GeoLocation = Invoke-RestMethod -Method Get -Uri http://freegeoip.net/xml/$ExternalIP $NTPGeolocation = $GeoLocation.Response.CountryCode.ToLower() } $GeoLocation.Response |
That can then be used as you see fit. Though for me, I’m using it to update the Group Policy being applied to the PDC Emulator to point to the country specific NTP Pool with the generic pool as backup value.
|
1 2 3 |
$NTPPool = "pool.ntp.org" if ($NTPGeolocation -ne $Null) { $NTPPool = "$NTPGeolocation"+".pool.ntp.org,0x09 "+"$NTPPool"+",0x0a" } get-gpo -all | where DisplayName -like "*PDC*" | set-GPRegistryValue -Key "HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\W32time\Parameters" -ValueName NTPServer -Value "$NTPPool" -Type String |
That’s how easy it’s to modify a Group Policy object.
Please share any solutions using GeoLocation in the comments. It might give me some nice new ideas too!